
Smarter Data Privacy Is Not Just Software
Safe AI isn’t just a step you add at the end. It’s a discipline you build into how data flows. This playbook shows security, data, and ML leaders how to one, keep a live map of sensitive data, two, apply proportional protections before training or indexing, and three, generate audit evidence automatically so you ship faster, with lower risk and fewer rework cycles.
What you’ll get: a live sensitive-data landscape, enforceable pipeline gates, and a simple scorecard to prove quality and compliance.
Step 1: Assignment, Alignment, Consent
Make privacy a shared responsibility with clear ownership and update consent for AI use.
Smarter data privacy starts with culture, not code. Leadership, engineering, and compliance align on privacy by design when someone owns outcomes. Without a named lead, efforts fragment and get ignored under deadline pressure. As AI products reach customers and patients, the privacy lead should partner with counsel to include AI modeling in consent.
Actions:
- Designate or confirm a single accountable owner for data privacy across acquisition, discovery, and AI use. Empower them to manage shadow data, enforce safe data practices, and engage external experts when needed.
- Review data usage consent with counsel and add clear AI language.
Example Language:
“We may use your information to improve the AI models that power [feature]. We apply de-identification and strict access controls, and we do not use your data to train models shared outside [Company] without your permission. You can opt out anytime in [settings].”
Step 2: Modernize Data Discovery

Continuously identify PII/PHI data across your environment.
Data is the hardest part of AI. You cannot protect what you cannot see, and plugging into an LLM will not work until you know what sits in databases, notes, emails, and logs. Discovery is not a one off. If it is not ongoing and automated, sensitive data slips into pipelines unnoticed. Use AI to start faster, then finish with disciplined review and quality controls.
Actions:
- Select a contextual and semantic discovery solution that inspects content (not just column names or simple regex).
- Build a baseline sensitive-data landscape across priority sources; capture what/where/how much/first-seen/last-seen.
- Schedule scans and assign source owners; track coverage percentage and freshness in a simple dashboard.
- Add parsers for free text, JSON, logs, and files to close blind spots.
- Log findings to an audit trail (source, field, entity, confidence, action taken).
Deliverable: Complete coverage, fresh dashboard, and the first “live landscape”.
Step 3: Evaluate Classification and Risk Profiling Capabilities
Classify PII and PHI with context and rank risk to keep a live landscape, not a static catalog.
Sensitivity changes with exposure, regulatory duty, and business impact. Shallow or stale classification over-protects low-risk data and under-protects critical fields. By “introspect the data,” we mean the system inspects values and their context—patterns, neighbors, and linkers (e.g., device IDs, store IDs, timestamps)—to infer type and risk so that controls are applied where they matter most.
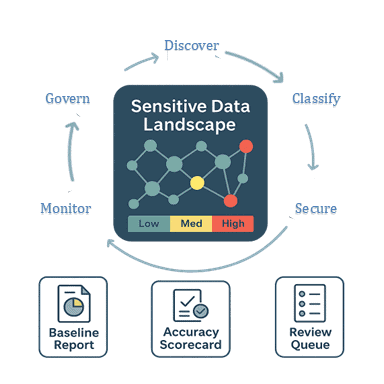
Actions:
- Validate accuracy with tiered thresholds on your data
- Build a labeled set (≈100–200 examples per high-priority entity) across structured tables, unstructured text, and JSON/logs; include edge cases, look-alikes, and linkers (e.g., device/store IDs).
- Measure per entity precision, recall, F1, plus 5–10 example hits/misses by source type; record confidence scores for review cutoffs.
- Set use-case targets exactly as above (Tier-1 ≥0.95–0.98 F1; logs/support ≥0.90; triage 0.80–0.90).
- Stand up a lightweight review loop: 48-hour SLA; record system label → reviewer label, reason, severity, and location; update rules/patterns monthly and re-run the sample to verify lift (keep a simple changelog).
- Quick QA guardrails: hold out ~20% for validation; zero known Tier-1 misses; cap Tier-1 FPs to protect reviewer bandwidth.
Deliverable: A one-page scorecard (thresholds, scores by entity/source, top misses, actions taken).
- Stand up a reviewer workflow & correction queue
- Create a simple “review needed” queue (Jira/Asana/sheet) for edge cases; assign an owner + SLA; capture snippet, system label → reviewer label, reason, severity, location. Roll recurring misses into updated rules/patterns and keep a changelog. This boosts quality without over-promising full automation.
Step 4: Secure Data
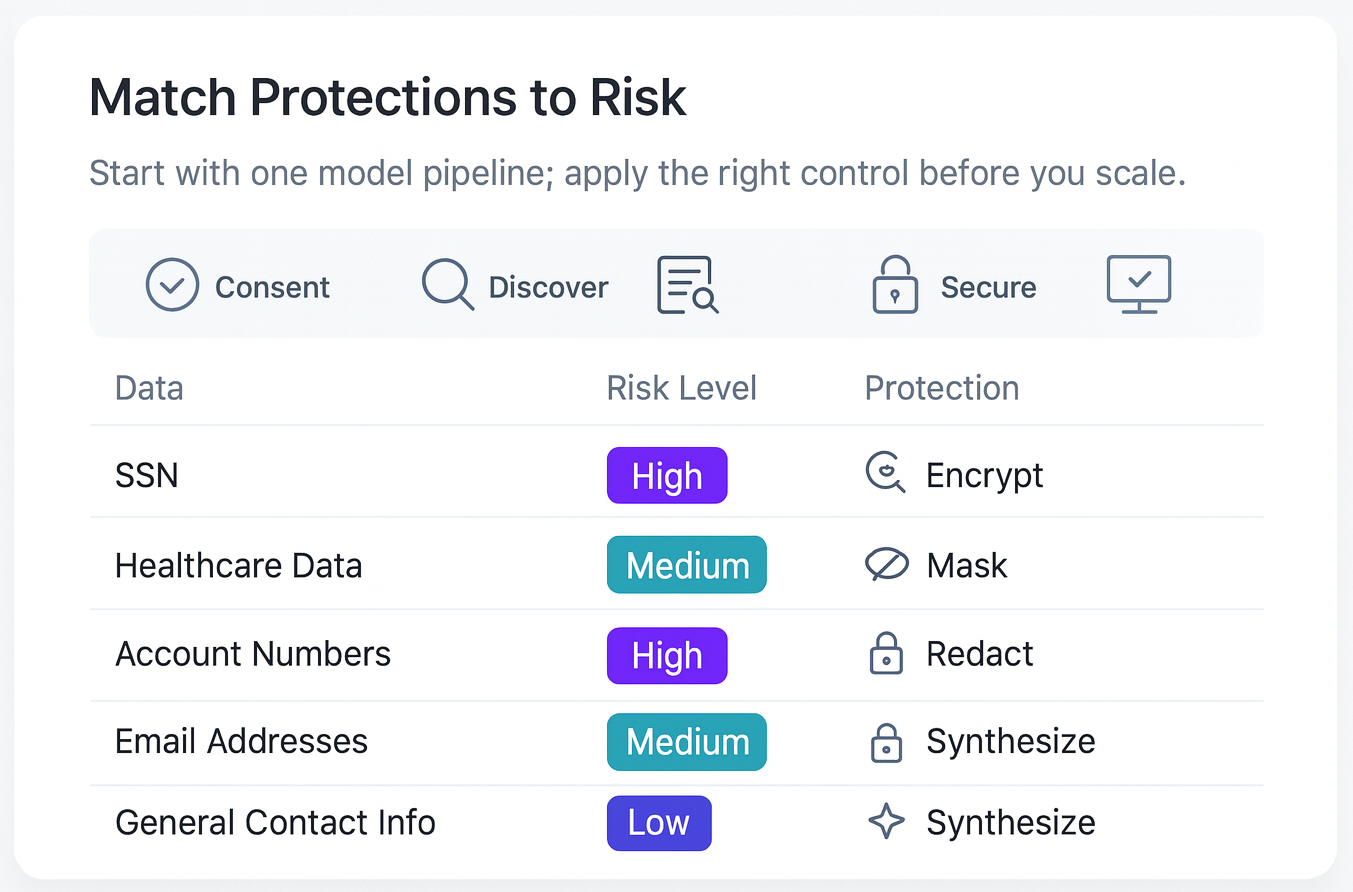
Protect the data before you train the model or index.
Discovery and classification only matter if you act on them. Securing data means fit-for-purpose controls by use case: synthetic data for safe model training, pseudonymization/de-identification for analytics, tokenization or format-preserving encryption when formats must be retained, and anonymization when reversibility must be impossible. If data isn’t secured upstream, risk flows into training corpora, embeddings/vector stores, and logs—becoming exponentially harder (or impossible) to remediate. Early action reduces liability, limits rework, and accelerates safe scaling.
Actions:
1. Map Controls to Use Cases – Start Small, then Scale
Review your de-identification toolkit and map each control to a single pilot pipeline first (masking, redaction, tokenization/FPE*, encryption*, synthetic data). Because PII/PHI is classified in context, reserve the heaviest protections for Tier-1 data and lighter controls where risk is demonstrably lower, conserving resources and speeding delivery.
2. Enforce Security Gates in the Pipeline
Gate A (ingestion): scan → label → auto-apply control → log decision.
Gate B (pre-train/index): Block if any Tier-1 remains; allow override only with justification and auto-audit.
3. Unify Discovery, Security, and Monitoring
Use (or integrate to) C2 to enforce protections and policies end-to-end with policy-as-code at ingestion and pre-training/index checkpoints, plus centralized audit/evidence packs and alerting.
Step 5: Govern Data
Build oversight into everyday workflows for data insights. Data is always changing.
Governance sticks when it’s automated. Use policy-as-code gates so every scan, decision, and override is written to the audit log. Maintain a live landscape with scheduled scans and clear ownership. Monitor new exposures, keep an exception register with SLAs, and generate evidence packs from the audit log, no separate audit projects required.
Deliverable: Monthly evidence pack (HIPAA/GDPR), exception register, policy rules repo.
Actions:
- Discovery gates at ingestion & pre-train/index: Scan every dataset; auto-apply masking/de-identification as required; block pre-train/index if Tier-1 remains; record decisions and overrides in the audit log.
- Maintain a live sensitive-data landscape: Keep the landscape current across priority sources with scheduled scans and clear ownership per source; track coverage and freshness at a glance.
- Monitor & automate: Run continuous discovery, alert on new exposures, keep an exception register, and generate evidence from audit logs when needed (no separate “audit project” required).
Data privacy with the right data discovery, security, and monitoring solution can speed up your AI development and improve outcomes. Reduce risk, increase efficiency, and build customer trust and loyalty.
Check Out NextGen AI Privacy Insights
Put Privacy Ahead of Speed
Building Responsible AI Applications


Privacy-first AI accelerates safe launches, reduces costs, avoids technical debt, and builds trust while boosting growth.
Embedding privacy from the start transforms compliance into an advantage, empowering agile, confident AI development.
Exploring AI and data privacy, with experts uncovering risks, solutions, and trust in responsible technology.